国家企业信用信息公示系统(广东)爬虫设计思路
现在的网站变了,不光是验证码,而且网站的整体结构也有也变化,这里面的大部分代码也都已经无效了。但其中一些解决问题的思路还是有一参考价值的
爬取的逻辑,定时轮询ftp服务器上的名单,如果有bank**.txt名单文件,并且相应的名称没有.ok文件,说明这个文件还没有进行爬取,那么把这个文件下载下来后,开始执行爬虫程序。轮询的程序在frcbRep中,爬虫程序在com包下,并且入口在这个方法里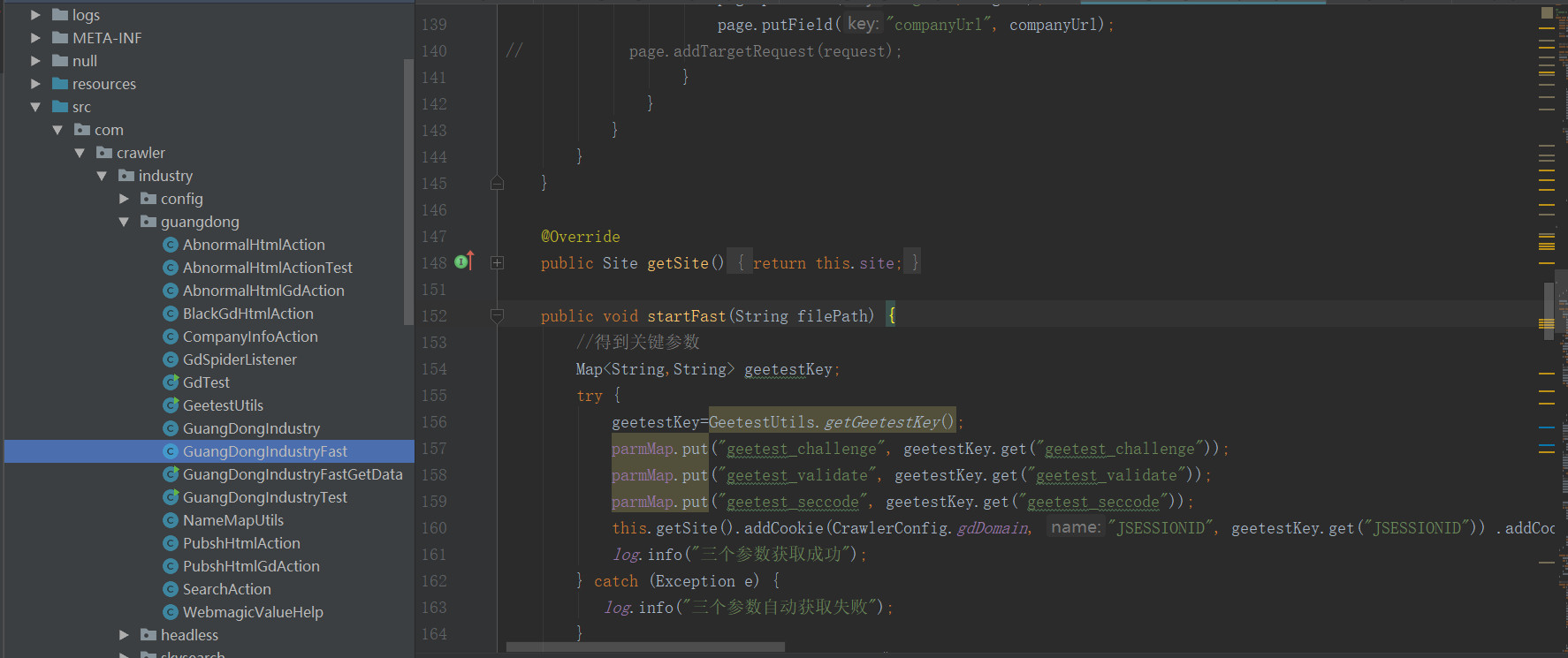 ,把下载下来的文件路径传入这方法。
,把下载下来的文件路径传入这方法。geetestKey=GeetestUtils.getGeetestKey();这行代码是为了得到3个关键的参数,这三个参数我要详细的说明一下。
三个参数
广东企业信用信息网站所用的极验是很老的那一种,当滑块划过后,只要长度对了,那么就能通过验证,并且生成3个参数。这三个参数加上查询的关键字,就可以查出相关的公司查询结果页,一般情况下,这三个参数只能匹配一个查询的关键字。但这个网站bug就在这个地方,这三个关键字可以配合cookie可以使用多次,查询不同的公司名,通过这个bug,我们只要滑动一次我们就可以得到这三个参数,然后,查询多次,根据我的发现,对方网站并没有对查询的数量作出限制,哪怕是ip也不会封锁,我利用这个特性,一个小时就爬取了两万条公司的查询结果页。geetestKey=GeetestUtils.getGeetestKey();所以这行代码就是为了得到3个查询参数,从而使后面的查询不用再去模拟滑块的动作。模拟滑块的动作是极奇消耗时间的,所以这种取巧的方法极大的加快了爬虫的速度。但也使代码的复杂度增加了,这个在配置文件决定是否使用他
301重定向
我们对这个这个老版本的js进行过研究,我们发现如果对这个js进行改编,完全可以不用计算滑块图片的缺口距离。只要滑动就可以通过验证,哪怕你滑动的距离是错误的。那么如何使访问这个网站的时候,把js变为我们的js呢,当时我的解决办法,就是通过操作phantomjs来把这个js 301重定向到我们本地的js,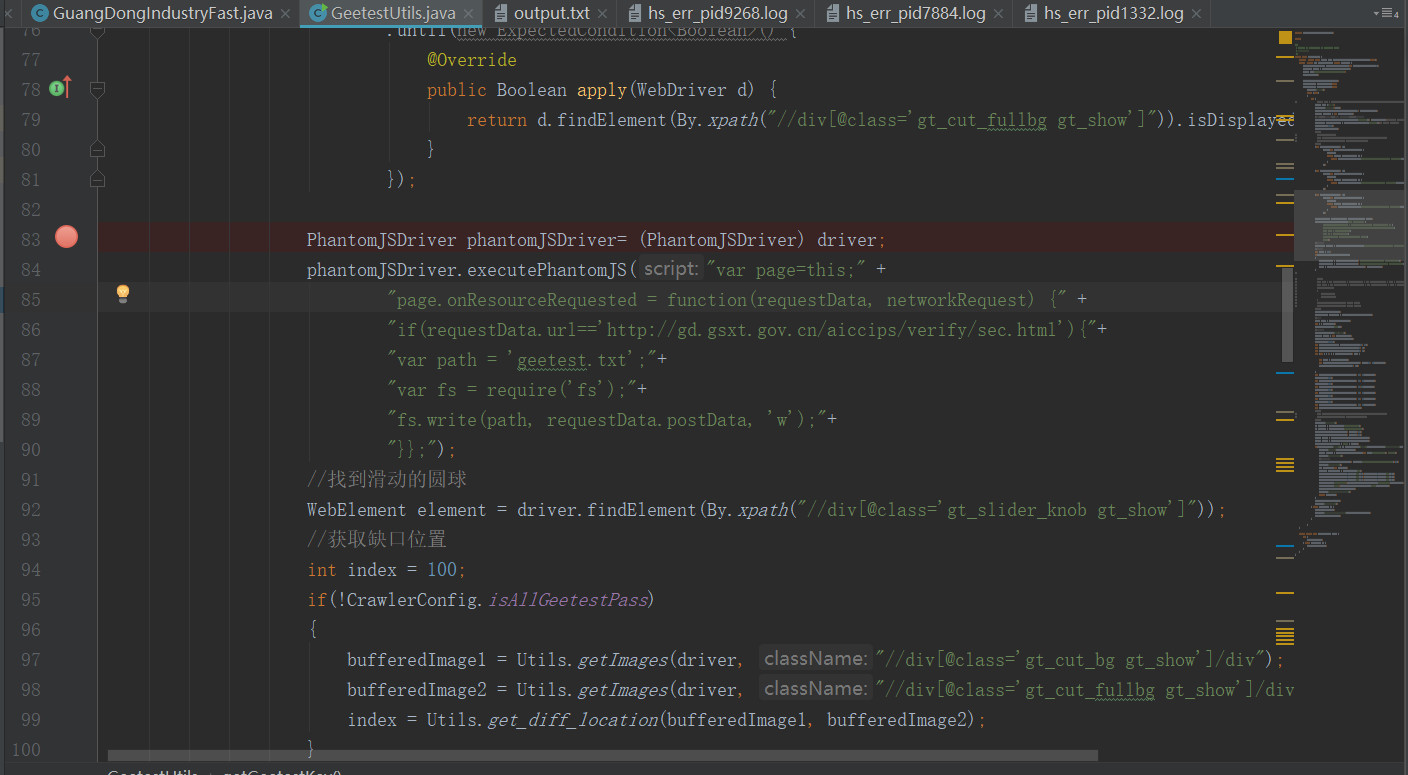 这样的话,就能执行我们给他定制的js了。这样随便滑动就可以通过,这样又省去了图片运算的时间,加快的速度,但这样,代码的复杂度又增加了。这个在配置文件决定是否使用他
这样的话,就能执行我们给他定制的js了。这样随便滑动就可以通过,这样又省去了图片运算的时间,加快的速度,但这样,代码的复杂度又增加了。这个在配置文件决定是否使用他
这个就是当时的修改的js文件
phantomjs如何和java通信?
这里来了个问题,phantomjs得到了那三个参数,这是他内部js得到的,和我们的js是没有啥关系的,虽然说上图中的phantomJSDriver.executePhantomJS()这个方法是可以返回一些东西的,但这种比较特殊,返回不了,这是一个难点,后来通过查询官网,我了解到phantomjs是可以写文件的,那么,得到了这三个参数后,生成这三个参数的文件,那么java在读取这个文件,从而达到了通信的效果。所以在上图中phantomJSDriver.executePhantomJS()这个方法我写了js生成三个参数的文件代码。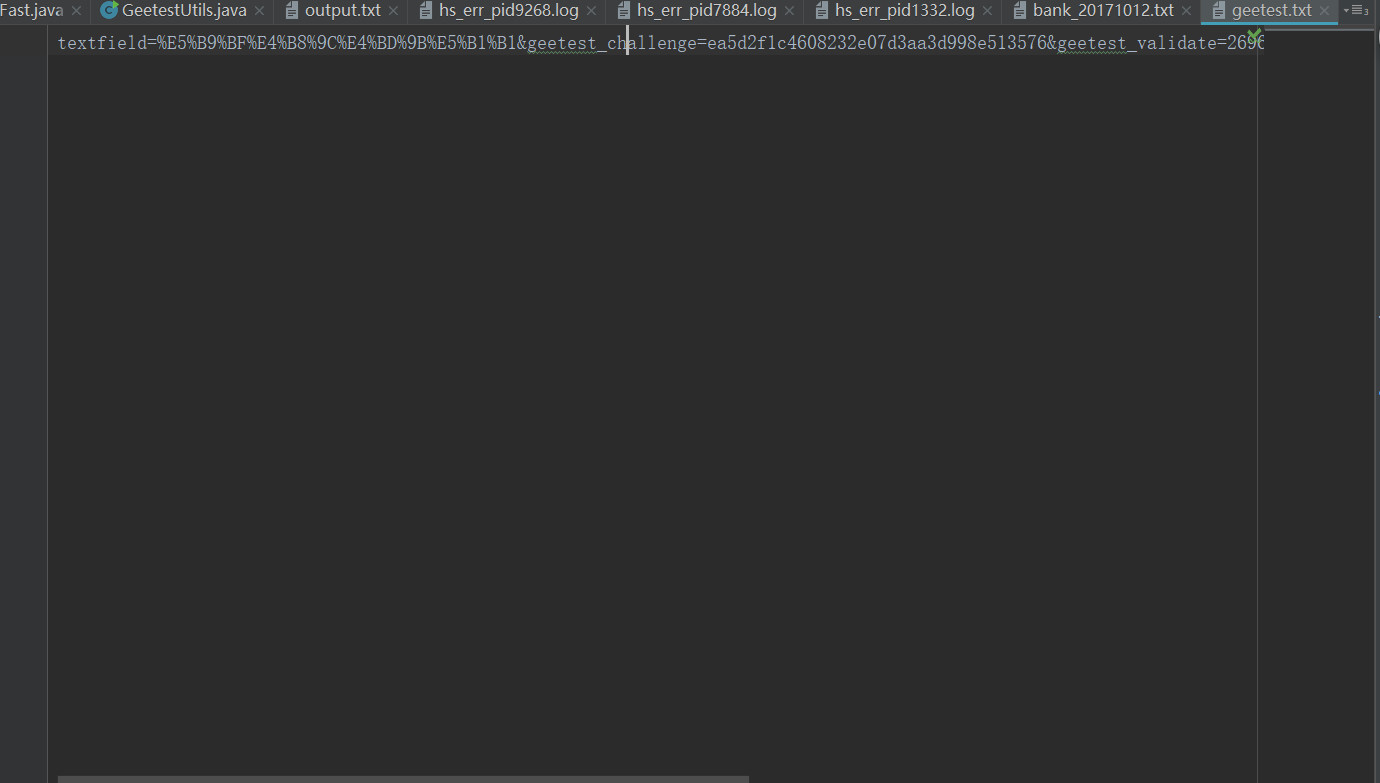
开始爬取了
得到了三个参数后,爬虫开始疯狂的查询公司名称,并且得公司页面的详情url,所谓的详情url就是我们要提取字段的最终页面的url地址,当时我是推测这个url应该是永久的,所以我加入缓存机制,查询后,把这个url存进去,如果下次再查询这个公司的话,那么就跳过查询阶段直接访问最终页面。这样又可以加快速度,但代码的复杂度又提高了,下图是我缓存的url,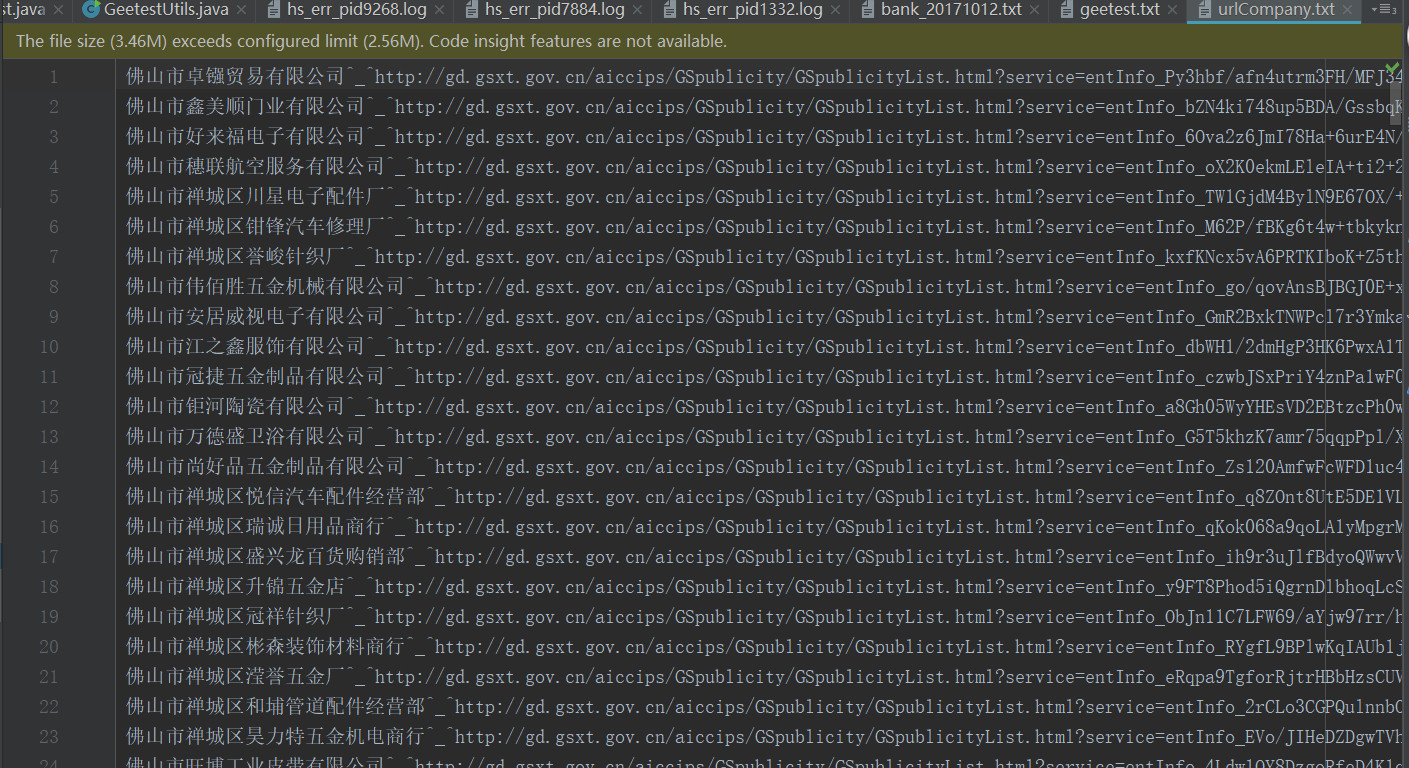
查询的逻辑是什么?
这是要查询的公司部分名单, 先是通过公司名称来查询,如果搜索的结果页为空,那么再用公司的组织机构号来查询,如果组织机构号也为空的话,那么这个公司的是查询不到的,这个时候程序又会生成一个查询不到的公司名单,下次再爬取的时候,就会忽略这个查不到公司的名单了,这样加快的爬虫的速度,但代码的复杂度又增加了。这里小问题,公司名单上有些有括号,这括号,又有点坑了,有的是中文括号,有的是英文括号,最麻烦的是企业信用网它的查询结果,括号也是有可能是英文的,或者是中文的,这对匹配查询结果又造成的麻烦,有的查询结果可能还有空格,所以我通通把括号和空格去了再去匹配,还有一个麻烦的是我发现有的公司查询出来的可能有多个,可能有的是注销了的,有的是没注销的,所以如果查询出来的结果有多条的话,那么再去匹配一下公司的机构号,这样的话也就万无一失了,也许还有更坑的东西我没发现吧。
先是通过公司名称来查询,如果搜索的结果页为空,那么再用公司的组织机构号来查询,如果组织机构号也为空的话,那么这个公司的是查询不到的,这个时候程序又会生成一个查询不到的公司名单,下次再爬取的时候,就会忽略这个查不到公司的名单了,这样加快的爬虫的速度,但代码的复杂度又增加了。这里小问题,公司名单上有些有括号,这括号,又有点坑了,有的是中文括号,有的是英文括号,最麻烦的是企业信用网它的查询结果,括号也是有可能是英文的,或者是中文的,这对匹配查询结果又造成的麻烦,有的查询结果可能还有空格,所以我通通把括号和空格去了再去匹配,还有一个麻烦的是我发现有的公司查询出来的可能有多个,可能有的是注销了的,有的是没注销的,所以如果查询出来的结果有多条的话,那么再去匹配一下公司的机构号,这样的话也就万无一失了,也许还有更坑的东西我没发现吧。
两个不同的结构
这个网站还有一个坑的地方就是公司的详情页可能有三种域名,其中两种网站的结构是一样的,这没什么问题,还有一种是深圳公司专有的网页结构,所以网页结构分为两种,我对这两种作了判断,深圳的是一套方案,非深圳的又是一套方案。这又把代码弄复杂了,哎。。。
对于是否经营异常企业的判断
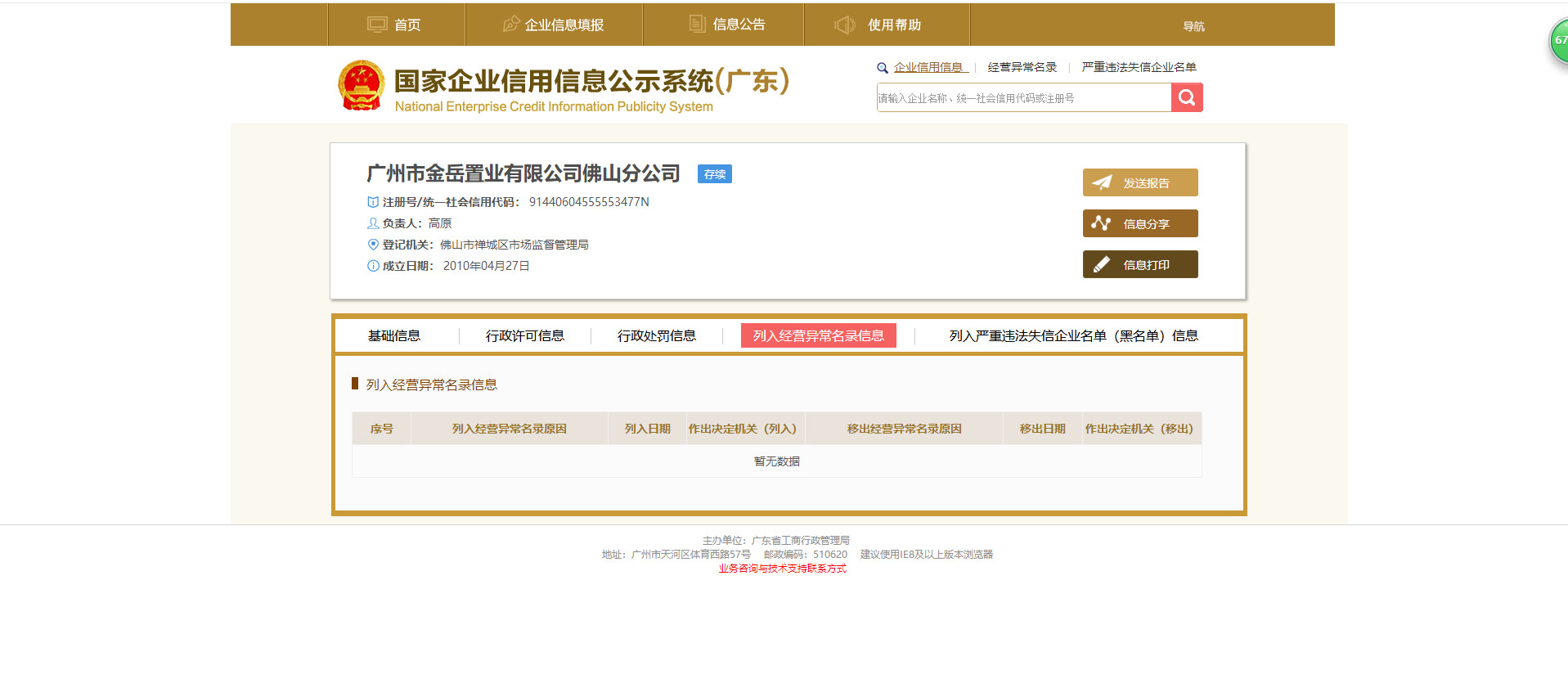
如果在这一页有记录,且没有“移除经营异常的记录”,那么这个企业就是有经营异常的。所以我是把异常的记录数量和“移除经营异常的记录”的数量作比较,看哪边大,从而判断这个企业是否有异常。
结果是什么

生成gov+日期.txt文件,和 日期.ok文件,再上传回服务器。
顺序是什么
1企业名称提取字段
companyNames=企业名称,名称
2注册号提取字段
regNums=统一社会信用代码/注册号,注册号,注册号/统一社会信用代码
3法人提取字段
legalPersons=法定代表人,负责人,经营者,投资人,执行事务合伙人
4营业期限至 提取字段
businessTos=营业期限至,合伙期限至
5注册资本提取字段
regMoneys=注册资本
6住所提取字段
addresss=住所,营业场所,经营场所,主要经营场所
7经营范围提取字段
businessScopes=经营范围
8是否列入经营异常名录
2代表没有经营异常,1代表有经营异常
9是否列入严重违法失信企业名单
2代表没有列入,1代表有经营异常
断点爬取
初期的方案是,把已经查出来的公司结果文件和待查询的文件比对,看哪些公司没有查到,如果没有查到,说明是上次没有抓完的,这种方式太过low了,现在方案是用redis缓存起来。
代理问题
由于当时需求是不要用代理,银行用那玩意不安全,找出对方网站的反爬虫方案来,我的研究结果是开五个线程把停顿的延迟变为1秒即可,但有的时候会不生效。也许是看对方的心情吧。现在方案是data5u这类网上的爬虫ip提供商来去爬取。