前言
由于这些天要进行一些交接任务,公司要求把所有相关爬虫的东西都总结成技术文档才算交接完成。所以干脆写篇java爬虫教程。我所学的一切都是网上自己找的相关文章,读Webmagic源代码而来,非常感谢网络上很多无私的人分享自己的代码,所以这篇教程我也分享一下,也许其中的方案并不是最好的,但至少能为后面的人少走点弯路。
首先我要说明一下,这个webmagic爬虫框架其实也是作者仿照python爬虫框架的而写的,如果你学完了这个java实现的爬虫框架,并且能读懂它的大部分源码,再学习python的pyspider及scrapy这类爬虫框架,是会非常快的,并且他们解决问题的思路其实也是可以从java的搬到python,或者从python搬到java上。
这篇文章不是为了手把手的教,只是描述学习的过程,记录一下学习的经验。和让后面学习的人少走一些弯路。所以过程略显跳跃。。。
开始
http://webmagic.io/docs/zh/ 。首先先把这篇Webmagic作者的文章弄懂就可以写一个简单的爬虫了。其中要注意的是作者介绍了一种注解的方式编写爬虫,这种方式虽然看起来简洁优雅,但这些注解并没有做到像非注解方式的灵活,而且注解的方式也增加了debug的难度,所以我并不推荐大家用这种方式写爬虫。
提取表达式
webmagic提取字段的方式有xpath与jsoup这两种。jsoup类似于jquery的选取方式,解析效率高,容易用肉眼写出提取表达式。但不推荐一开始就用这个,后期优化效率可以用这个。xpath的原理就是dom4j的xpath表达式,表达式一般要借用chrome插件,用了这个插件后,开发时会很快
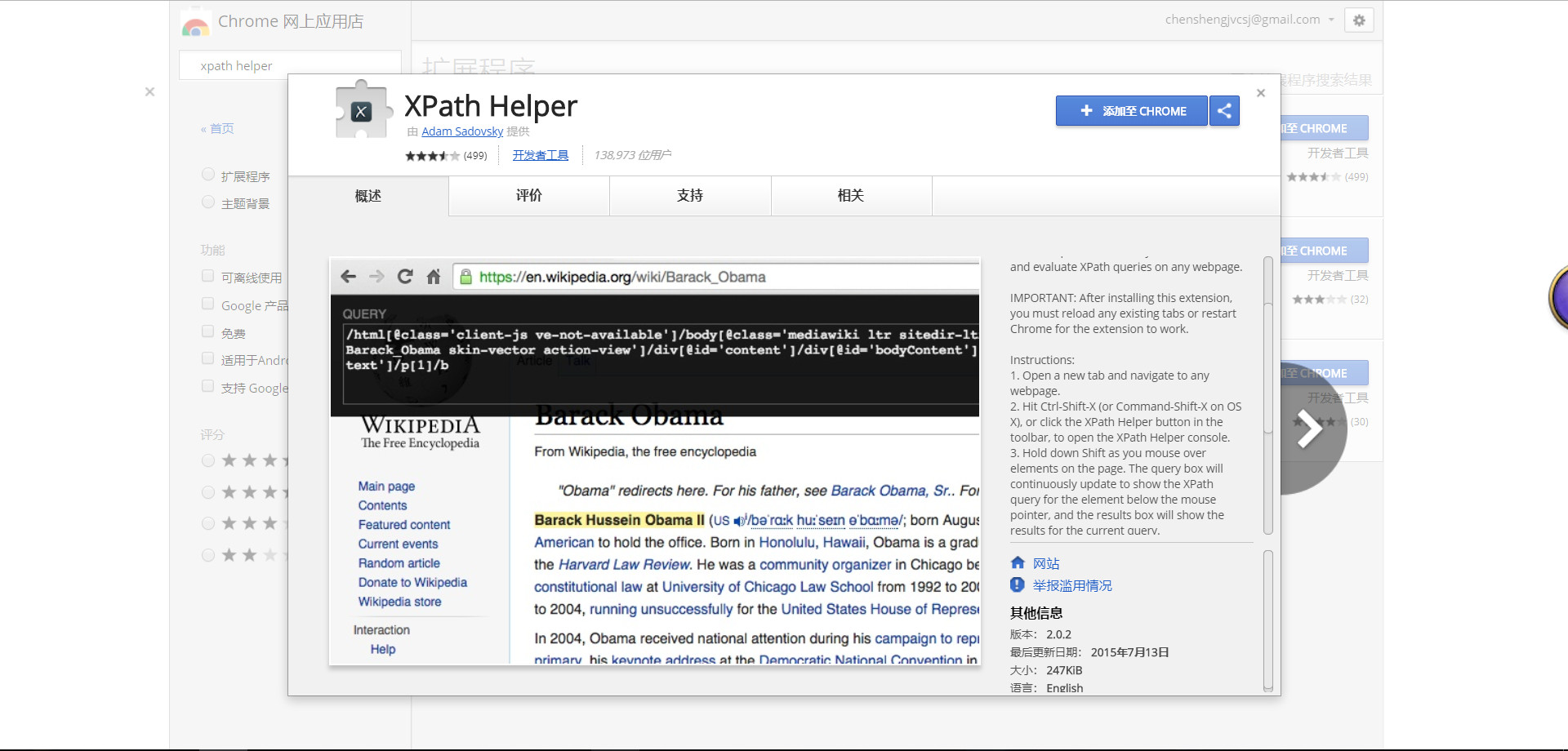
xpath helper,这个插件的用法读图中的英文介绍就能知道怎么用了,就不啰嗦了。
如果想要提取文章标题的xpath表达式,使用xpath helper插件后,可以简化一下表达式(注意,表达式太过于长的话,也许是会报错的)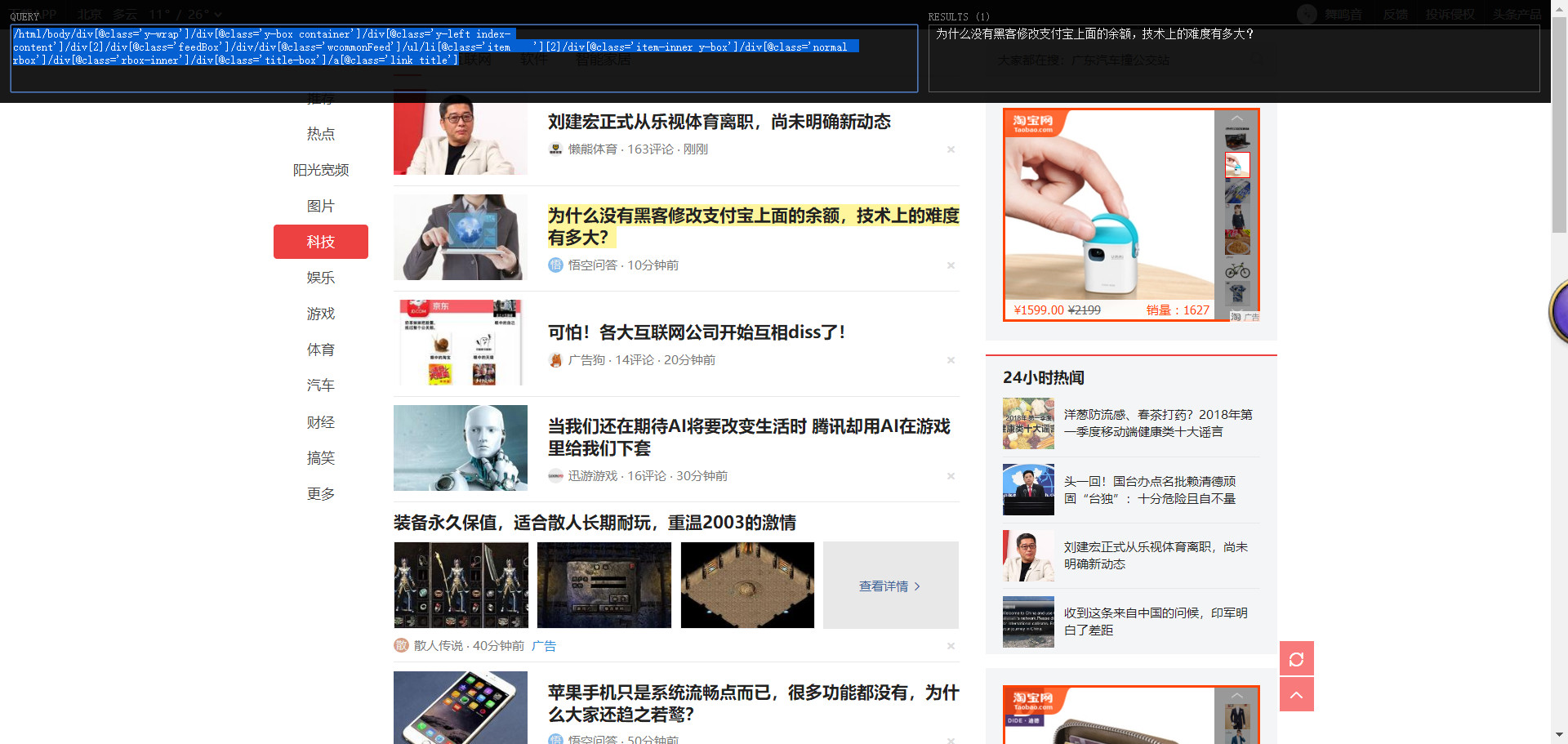
我们只取最后一部分,然后使开头为“//”代表非根路径,然后图中的标题也都选中了,说明这种简化表达式是ok的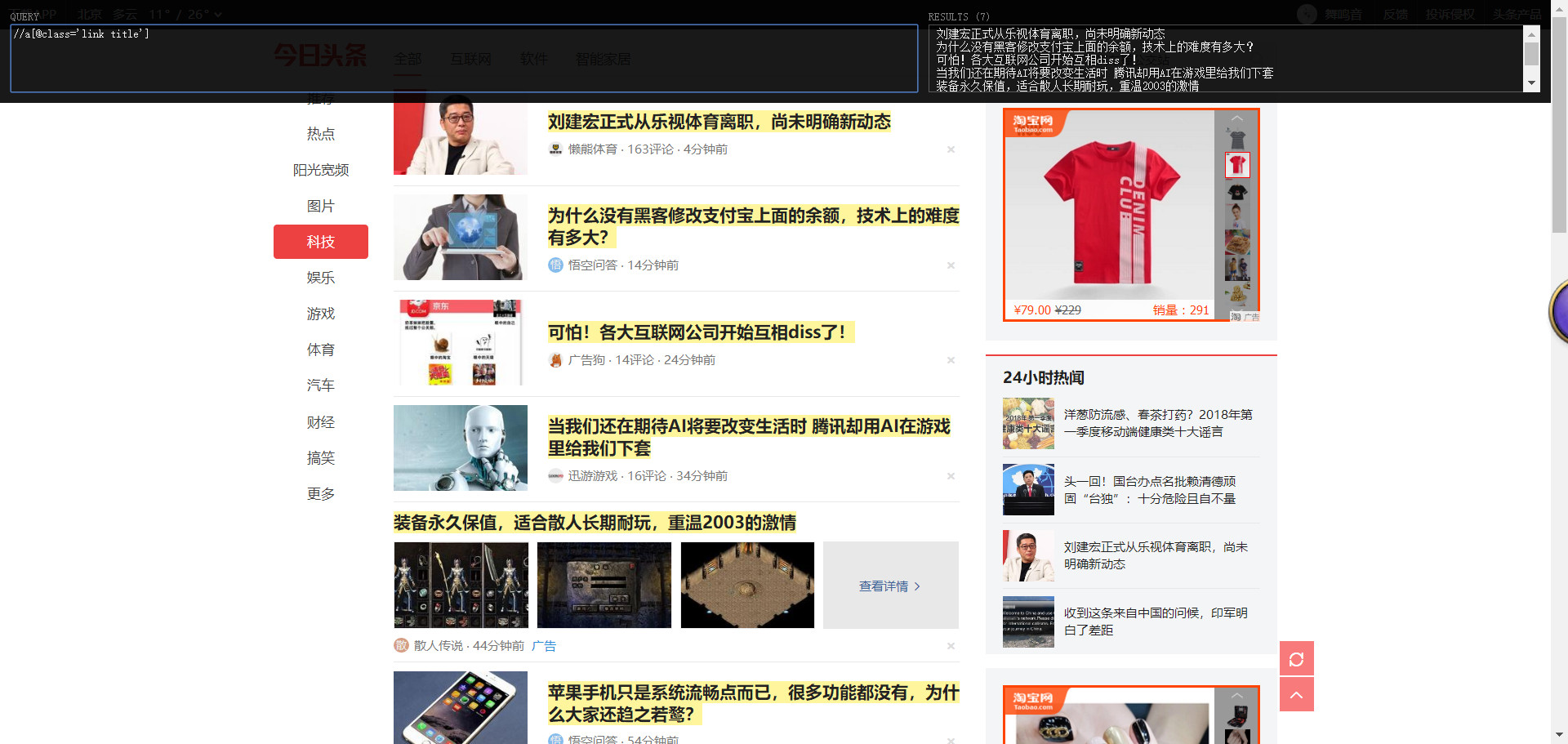
读者看完这些后,其实可以找个网站实战一下了简单的爬取了。
Request对象
这个对象看起来不怎么起眼,其实,能实现的功能有的时候非常强大,但官网中又没有对他进行详细的介绍,当时也是坑在这上面了。这里介绍他的常用方式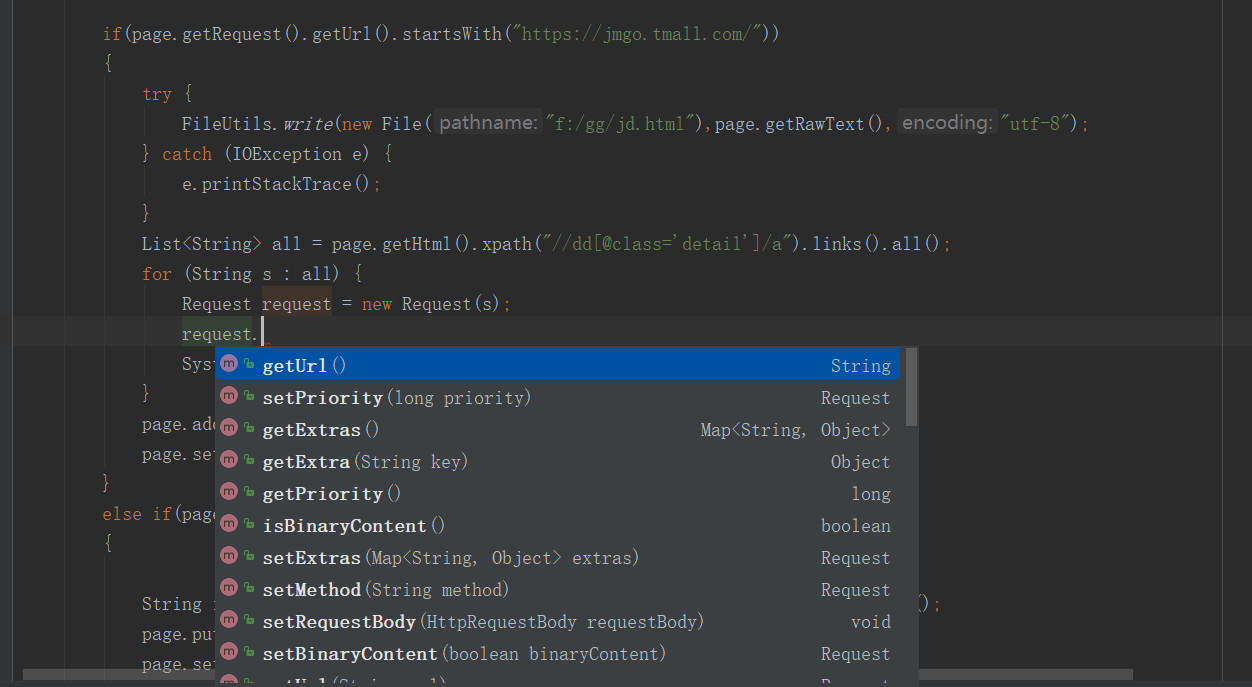 。
。
request.setPriority(0)
第一个方法’request.setPriority(0)’这个方法是设置这个url在当前url队列中的优先级的,在默认情况下,url的队列是遵循FIFO(先进先出)的方式,但有时,我们觉得这个url优等级比较高,比如在爬取天猫的时候先搜索得到商品列表url,再得到商品详情页的url,再提取信息,这个时候由于商品url列表在队列的最前方,商品详情的url在队列的后方,那么只有等到最后面,爬虫才会爬取商品详情。可能在数据量不多的时候不会有什么问题,但数据量多了话,要等很久才能爬到商品详情页,有的时候万一项目宕机了,那还没爬取到详情页就gg了,那之前的功夫也就白费了(当然这可以用文件或者redis实现断电续爬的功能),所以要设置优先级。数越大,优先级越高。当然一定要设置spider.setScheduler(new PriorityScheduler());这是url队列在内存上的一种设置方式,也可以用spider.setScheduler(new RedisPriorityScheduler("localhost"));这种方式,这样url队列是在redis上了,在redis上的好处是能实现断点续爬,并且能实现多机器分布式。
request.setBinaryContent(true)
如果你想把图片的url放入url队列,那么可以使用这种方式。判断是否图片用request.isBinaryContent();方式。这个方法的好处是免去了webmagic把图片转成文本的不必要步骤。
request.putExtra()
这个方法的主要用途是,如果你想在子url中得到父url的相关信息,那么在父url那么可以把相关的信息设置进去。然后用page.getRequest().getExtra()来提取当时在父url放置的相关信息。
request.setMethod(HttpConstant.Method.POST);
如果你想使用post请求那么可以使用这个方法,注意,如果请求是post的话,即使是相同的url,也不会进行url去重,request.setRequestBody(HttpRequestBody.form(parmMap, "utf-8"));
post表单这样就可以设置进去了。
request.addCookie()
如果请求需要特定的cookie的话,那么可以用这种方式。在Site对像使用这个方法,即为全局cookie
网页渲染的网站如何爬取
这个有几种方式,如何这个网站只是简单的把json渲染,那么用page.getJson().jsonPath()就可以搞定了。
如果这个网站特意做了反爬虫,那么只能用无界浏览器来了,无界浏览器分为几种,
htmlutil
一种是纯java实现的——htmlutil。这个的特点就是快,如果你想在java中执行javascript,那么可以用这个,但如果是渲染js那还是不要用这个方式了,因为它并不完全仿真浏览器。
Selenium
这个工具本意是用途自动化测试用的, https://www.seleniumhq.org/ (可能要翻墙)它可以结合chrome,firefox,IE,phantomjs,不过也用于爬虫。不过用这个速度启动偏慢。
phantomjs
这个可以说是爬虫中的大杀器了,因为它就是真的浏览器的内核实现的,webkit内核。模拟真实访问难以分辨,而且这个是没有界面的,所以爬的速度是超过有界浏览器,但慢于httpclient。这是 http://phantomjs.org/api/ 官网,遗憾的是由于chrome在最新的版本中也加上了无界的特性(headless),使phantomjs的作者感觉这个项目已经没有维护的必要了。在2017年4月的时候,phantomjs作者正式说明停止维护。 https://www.oschina.net/news/84158/vitaly-stepping-down-as-maintainer
虽然如此,但大量的老项目仍然还是使用这个无界浏览器,所以学会这个也是有用的。而chrome推出的这个新功能的浏览器,我在2017年12月份的时候到官网研究过,发现这个东西那个时候还没有完善起来。现在也不知道完善到什么程度了。
Selenium操作phantomjs的方法
一种是用Selenium来操作,由于phantomjs不维护了,最新的selenium已经不支持phantomjs了
http://phantomjs.org 下载phantomjs。
1 | <dependency> |
这是入门级Demo:
http://www.cnblogs.com/shirandedan/p/6802763.html
https://my.oschina.net/flashsword/blog/147334
好文章推荐:https://zhuanlan.zhihu.com/p/25507989
https://www.jianshu.com/p/9d408e21dc3a
截屏方法:
1 | File file=((TakesScreenshot)driver).getScreenshotAs(OutputType.FILE); |
这是我仿照例子写的驱动池。目地是为了解决phantomjs不支持多线程的问题。我其中注解的东西,可以根据实际情况使用他。
1 | package com.crawler.selenium; |
纯js操作phantomjs的方法
入门级Demo: https://blog.csdn.net/imlsz/article/details/24325623
下载的phantomjs有的example文件夹,里面都是例子,可以和 http://phantomjs.org/api/ 结合起来学习。
这种方式,相比Selenuim的方式,要麻烦不少,但他非常的快。
CasperJS操作phantomjs的方法
casperJs是对操作phantomjs的js进行了一次封装,相比纯js的方法要简单不少,我没有用过,不过看过一个开源项目,有个大佬用这个来操作phantomjs破解极验。(当然是以前的极验)。官网: http://casperjs.org/
这是这个大佬开源项目的地址: https://gitee.com/shentong_012/YayCrawler
这是casperJs和java相关代码:
1 | package yaycrawler.common.utils; |
Headless Chrome
这个上文提到的让phantomjs作者失业的新一代无界浏览器,也许是将来流行的无界浏览器。
官网:https://developers.google.cn/web/updates/2017/04/headless-chrome
下载:https://sites.google.com/a/chromium.org/chromedriver/
webmagic结合Selenium模拟点击动作
这个刚开始确实是个难题,直到我看到了这个文章: https://segmentfault.com/a/1190000008194764
所以借鉴这个思路,我自己实现了一个selenium的下载器,它可以放置动作,切换下载器。可以参考一下
1 | package com.crawler.selenium; |
1 | package com.crawler.selenium; |
1 | package com.crawler.selenium; |
我用这个在天眼查网站上进行过翻页爬取。天猫还没试过
断点继爬
webmagic自带的方案是文件系统,和redis,
文件系统:spider.setScheduler(new FileCacheQueueScheduler(""))
redis:spider.setScheduler(new RedisPriorityScheduler(""));
但遗憾的是这两种方式在我使用中和读源码后发现都有一定的缺陷(0.7.3版本中)
所以我自己实现了一种redis断点的方案
1 | package com.jgs; |
1 | public interface CanBreak { |
1 | package com.jgs; |
main方法中
1 | Spider spider = Spider.create(webmagicXfplay).addUrl(urls).setDownloader(httpClientDownloader).addPipeline(new ImagePipeline()).thread(5); |
代理问题
有的网站做了反爬虫处理,如果一个ip访问次数达到一个峰值,那么就会封了这个ip
这时我们只能找代理了,网上有很多免费的代理,但都不一定好用,因为,代理ip分为三种,
透明代理:网站知道你用了代理,也知道你原来的ip是多少
匿名代理:网站知道你用了代理,但不知道你原来的ip是多少
高匿代理:网站有知道你用了代理,也不知道你原来的ip是多少
而网上的一些免费代理大都是透明,或者匿名代理。
有的变态网站,只有你用了高匿代理才行。。。。
我个人用过三类代理:
http://www.data5u.com/ (质量不错,态度冷淡)
我用的是爬虫代理,访问一次api返回一个,但这个每秒只能请求两次,多了就不给你ip了。。。
所以可以用木桶算法来进行限流
1 | package com.crawler.proxy; |
http://h.zhimaruanjian.com/ (能用,质量不清楚,态度一般)
http://www.xdaili.cn/ (动态代理在2017年11月老是听说不太稳,现在不知道怎么样了,不过态度不错,动态代理不能用于无界浏览器)
这三类代理都各有特色吧,说不上谁好,只能说挑适合自己的
Seleninum+phantomjs动态设置代理的问题
这个问题困扰了我一段时间,网上都没有这方面的教程,后来我自己去啃源码和英文文档才知道方法PhantomJSDriver.class.cast(webDriver).executePhantomJS("phantom.setProxy('"+proxy.getHost()+"', "+proxy.getPort()+")");
phantomjs+js仿照这个也可以动态设置
Seleninum+chrome设置代理的问题
1 | CHROME_PATH = SeleniumConfig.chromePath; |
但遗憾的是我并没有找到动态设置代理的方法,启动完chrome后,除非关了这个chrome,再重启,要不然没有办法。也许现在新的chrome有方式可以办到吧。
验证码
这个可以用TesseractOcr来识别,但难度挻大,搞定这个,也就成了图像识别高手了。所以最简单的方法是用打码平台。
在很久以前没有机器学习的时候,打码平台背后是一群真正的人来手工打码,但有了机器学习后,打码平台也用上了这玩意。但有的时候我们也可以利用机器学习来训练。可能机器学习听起来很难,但如果只用用他的api的话,也是可以做到不错的效果的。可以用TensorFlow或者Darknet来,这方面我也不是很懂,也是我的同事做过这方面的事。
极验
https://zhuanlan.zhihu.com/p/28492887
https://blog.csdn.net/u011153869/article/details/71077415
这是当初极验的一些破解方法,当然现在已经没有用了,但这仍然有一定参考的价值。
爬虫分布式
爬虫分布式咋一听,好像是个高大上的东西,但我了解过后反而有点大失所望。所谓的分布式只是把url的存取队列改成了redis,这样多台机器上的爬虫程序共享这个队列,这样就可以通过加机器来提升速度,这也就是分布式爬虫,我以为只是wemagic这么实现的,后来粗略学习了下scrapy,发现分布式爬虫也就这么回事。`spider.setScheduler(new RedisPriorityScheduler("localhost"));用这个方法就可以是分布式了
https://gitee.com/shentong_012/YayCrawler 这个项目反倒有点分布式的意味。